
This work matured throughout 2019 in various conferences, round tables and workshops (www.cloderic.com), it was formalized early 2020 to be published in the proceedings of EGC (www.cloderic.com).
The explainability of AI has become a major concern for AI builders and users, especially in the enterprise world. As AIs have more and more impact on the daily operations of businesses, trust, acceptance, accountability and certifiability become requirements for any deployment at a large scale.
Explainability, a key part of the AI industry strategy
Explainable AI (XAI), as a field, was popularized by the eponymous DARPA program (www.darpa.mil/attachments/XAIProgramUpdate.pdf) launched in 2017, with the goal of creating a suite of machine learning techniques that produce more "explainable" models while maintaining a high level of learning performance, thus enabling human users to understand, trust and effectively manage the emerging generation of AIs.
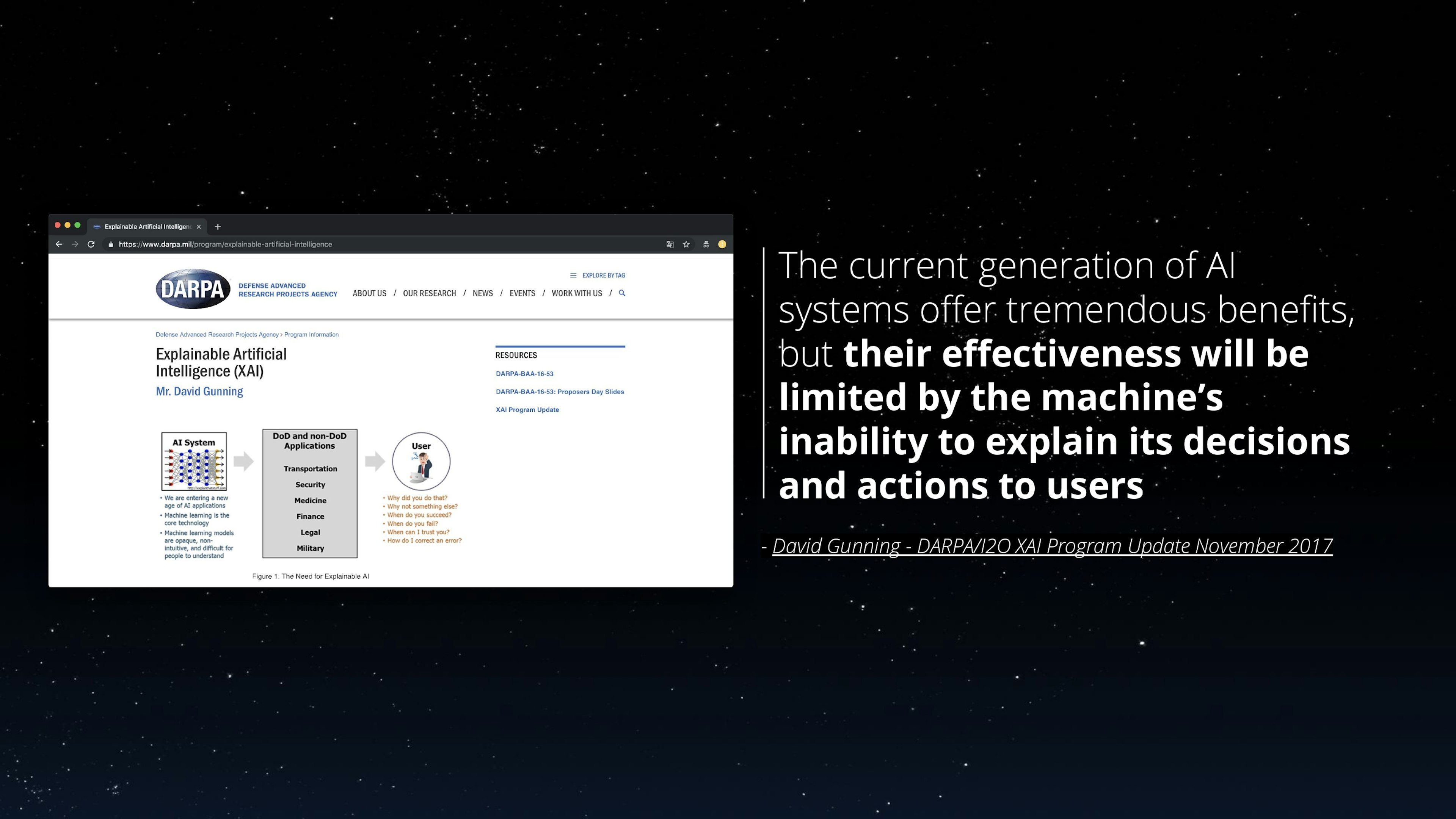
Over the past 5 years, explainability has become an important part of the AI discussions and strategies. Everyone talks about it:
- Research institutions, such as DARPA, in the US, or Inria (www.inria.fr/actualite/actualites-inria/intelligence-artificielle-les-defis-actuels-et-l-action-d-inria), in France, and even governments from the Obama administration (obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf) to Macron's government through the Villani report (www.aiforhumanity.fr/pdfs/9782111457089_Rapport_Villani_accessible.pdf) makes it an objective ;
- Big tech corporations, publish open source tools libraries such as Microsoft Interpret (github.com/interpretml/interpret) or IBM AI Explainability 360 (github.com/IBM/AIX360) but also release dedicated services such as Google Explainable AI (cloud.google.com/explainable-ai)
- Major data science players, software vendors and services providers alike, makes it a key part of their offering such as Dataiku (blog.dataiku.com/announcing-dataiku-7-now-with-deeper-collaboration-and-more-granular-explainability), Accenture (www.accenture.com/us-en/insights/technology/explainable-ai-human-machine) or Quantmetry (www.quantmetry.com/les-livres-blancs/),
- Startups are launched with explainability as a core benefit such as xplik (www.xplik.ai), DreamQuark (www.dreamquark.com) and of course, the company I co-created craft ai (www.craft.ai)!
That's not all, XAI is gets discussed by AI influencers, MOOCs and conferences are created to discuss about it!




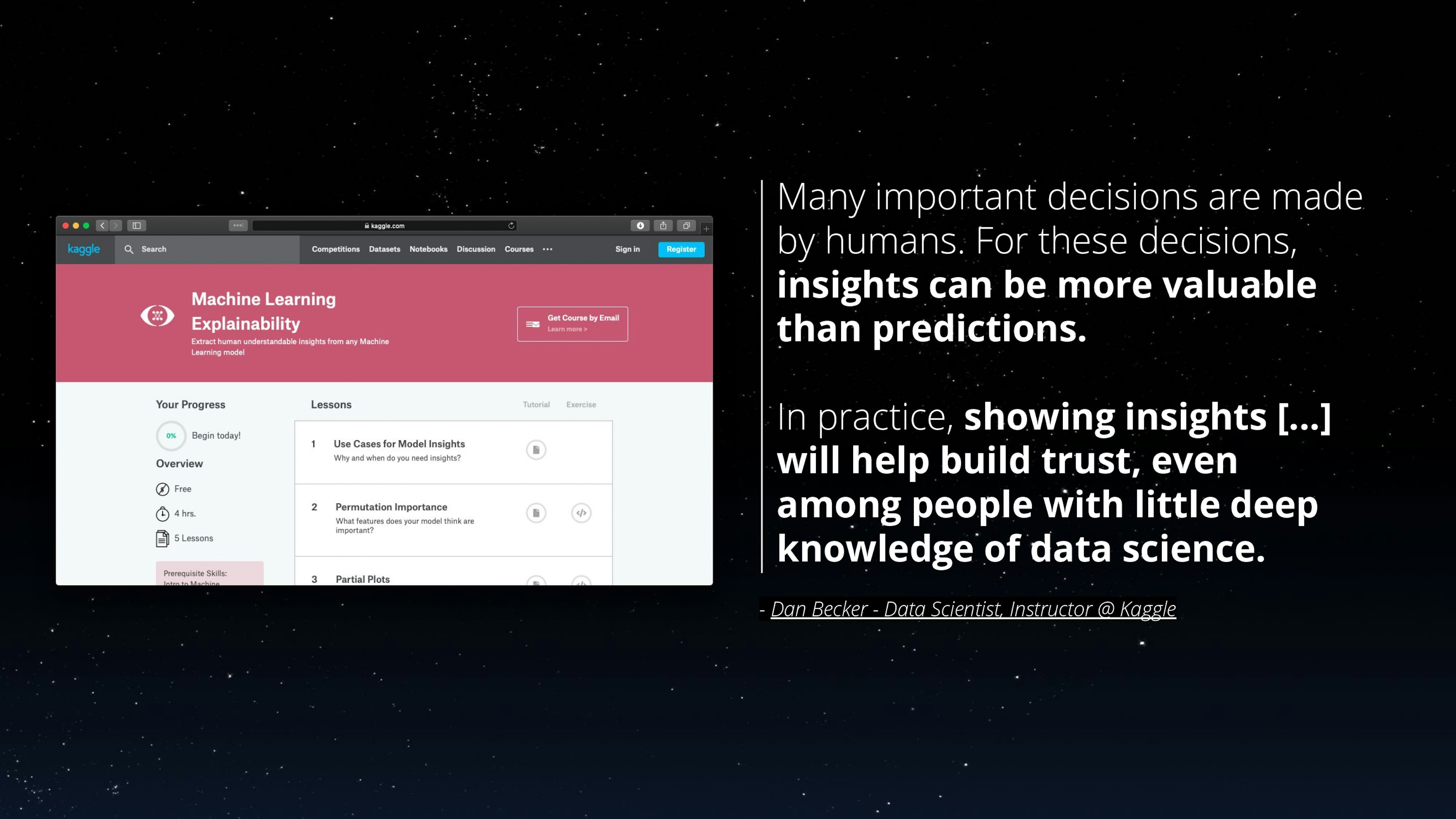

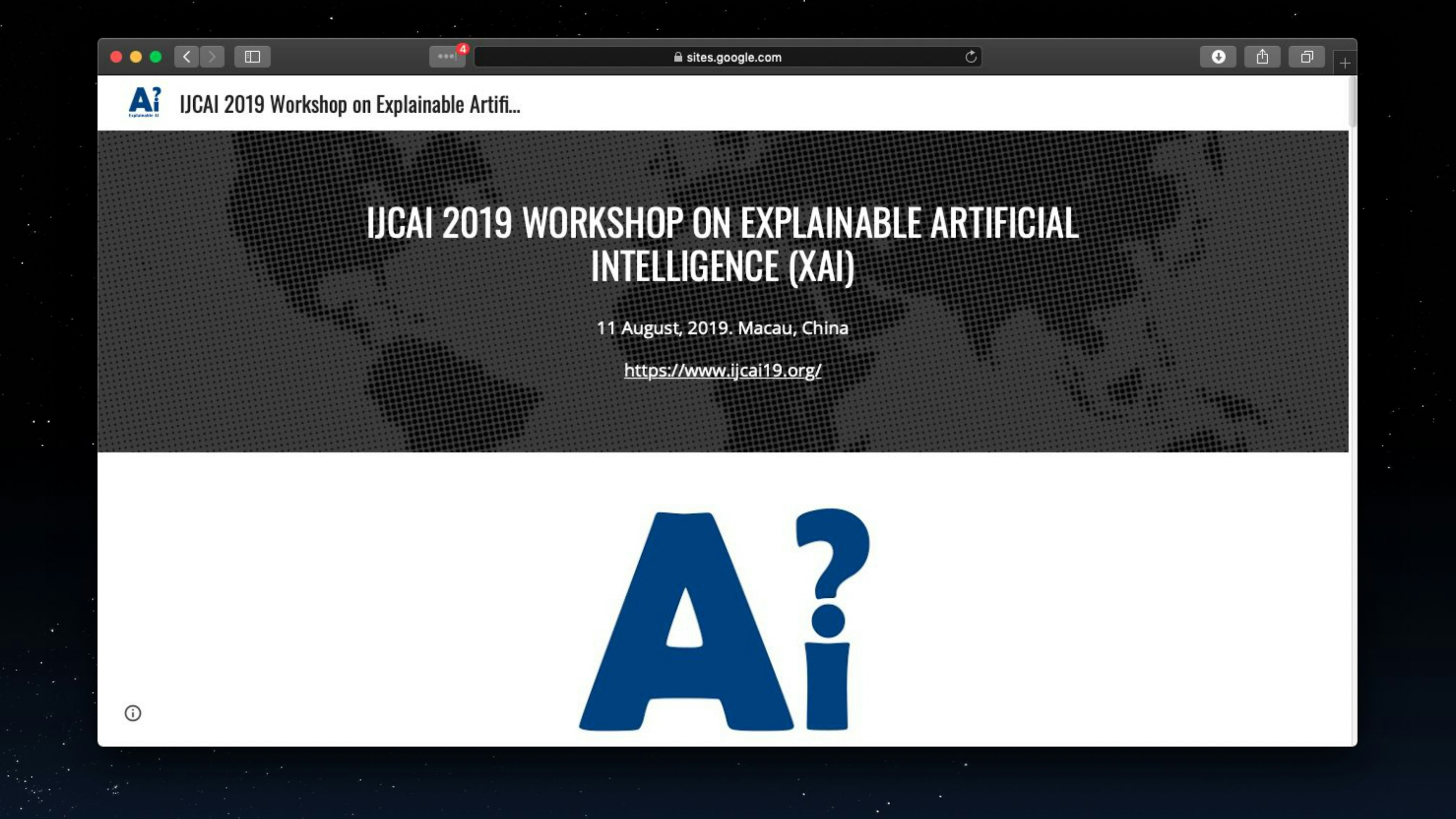
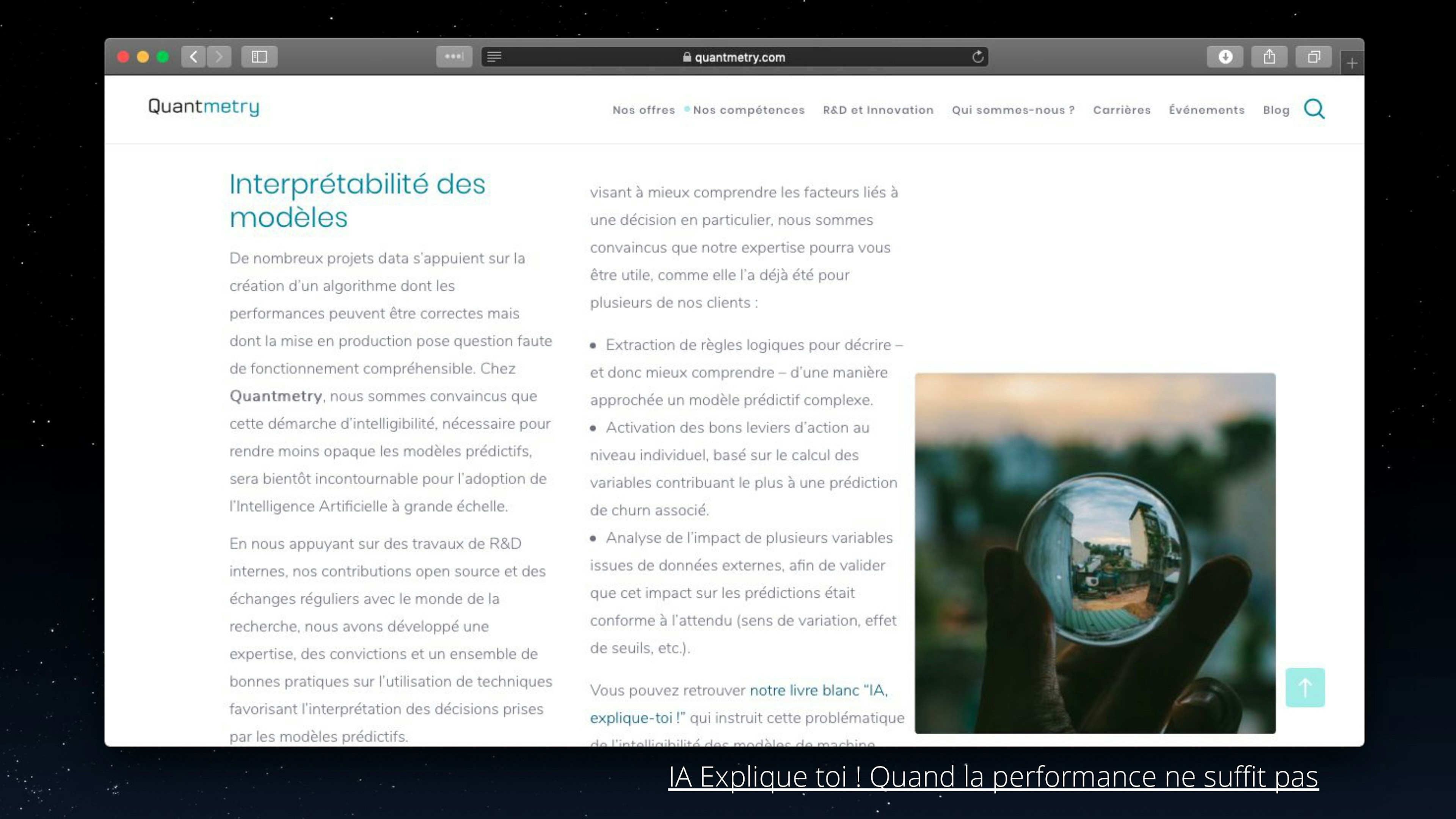
Explainability is important, everyone seems to agree!

This article aims at exploring why it is important, what impact explainability has when deploying AIs in the real world.
What is an explanation?
Before talking about Explainable AI, let's talk about explanations! XAI is about providing explanations regarding an AI to its stakeholders, it is therefore interesting to look at how people explain their decisions to each others. To help design and understand XAI, we can benefit from the learnings of social sciences on explanations. That's exactly why, Tim Miller (arxiv.org/abs/1706.07269) studied works from various branches of social sciences from philosophy to cognitive sciences and psychology.

The first learning extracted from the surveyed body of work is that people seek to build a mental model of how stuffs make decisions, how they react to a change in context, in order to anticipate them and reason about them. Explanations are a way to build such models much quicker than through observation only.
Because mental models are inherently subjective, good explanations are biased towards the explainee to match their perspective and their preexisting knowledge. In the real world examples we describe in the later sections, we found that the work of understanding the point of view of the explainee is a major part of the design of XAIs.
Another major finding is that good explanations are contrastive. It is not about answering "why has event E occurred?" but rather "why has event E occurred instead of event C?". We found out that the capability to generate such constrative or counterfactual explanations is quite important in the deployed systems we describe later (www.cloderic.com).
Miller argues that Explainable AI as a field should be considered at the crossroad of Social Science, Human-Computer Interaction and Artificial Intelligence. Taking a more practical approach, in this article we will take the point of view of the people and systems interacting with AIs, and study how explainability impacts these interactions in terms of features, acceptance and capacity to be deployed.
Non-explainable AI
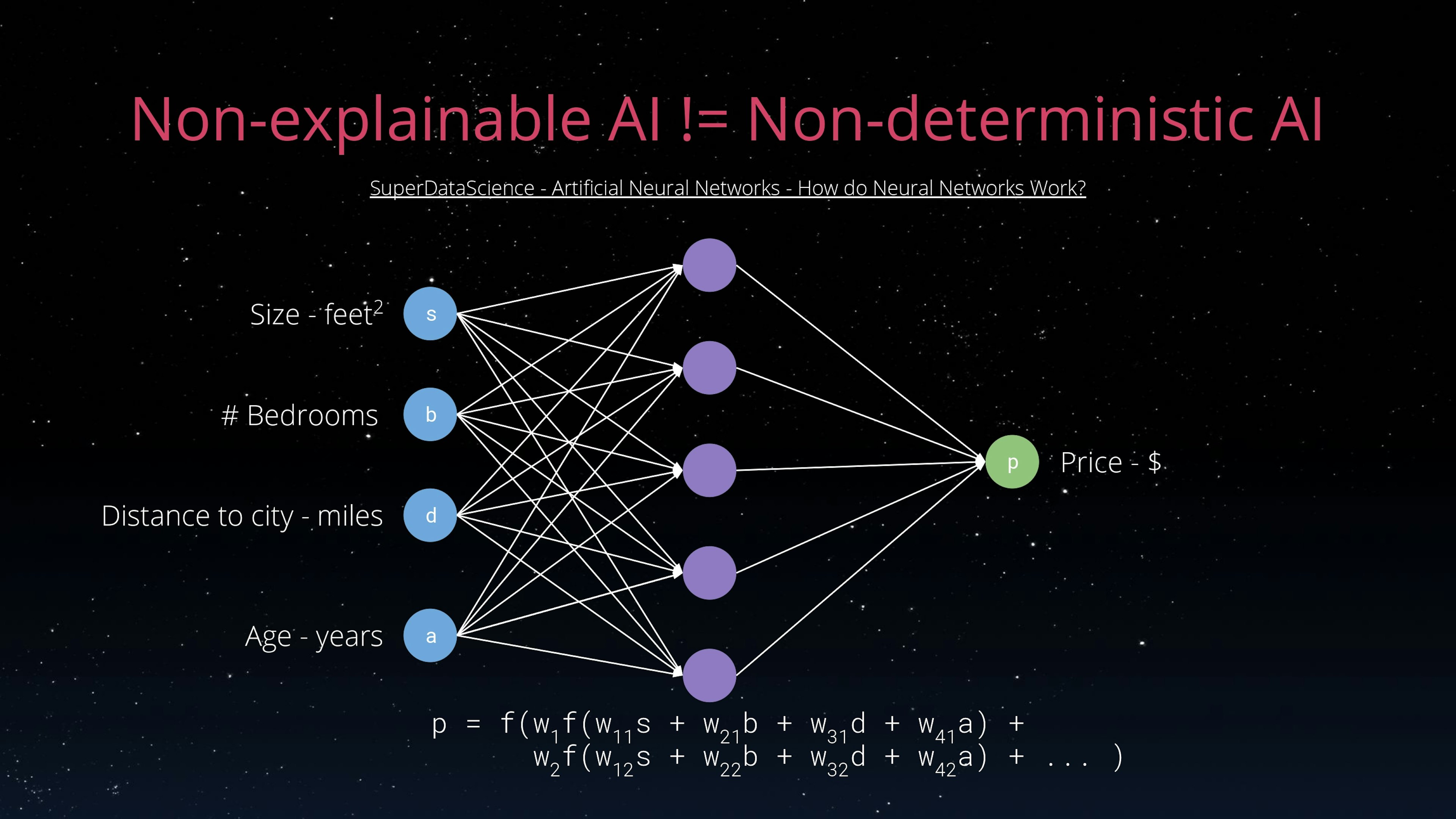
Let's do a last detour before actually talking about XAIs, let's ponder what makes an AI non-explainable and also let's talk about the difference between explainability and determinism.
Neural networks (NN) are often considered to be the epitome of black boxes, of non explainable AIs. To understand why you need basic understanding of how NNs work (www.superdatascience.com/blogs/artificial-neural-networks-how-do-neural-networks-work): each neuron in the network computes a linear combination of its input variables using learned coefficient and then applies an activation function to the result, each layer of neurons works on the previous layer output, up until the actual input variables. The result of the NN from a given input is therefore basically a linear combination of linear combinations, of ... of the input variables.
This basically means two things:
- The NN computation can be written down as a (large) equation and computed by hand, there is no magic, just maths, from a given input the output will always be the same, a NN is completely deterministic ;
- Unless the NN is really small, it is really difficult to understand how a variation in the input will impact the output: weights interactions are difficult to grasp and dimensional analysis is not possible, as the computation just manipulate numbers with no regards to their quantity.
In short, basic maths makes it easy to apply a NN to an input, the nature of the computation makes the output very difficult to predict its behavior. That what makes NN non-explainable, even the best specialists have a hard time creating mental model for a trained neural network.

The asymmetry between easy to compute but difficult to understand makes it a good target for adversarial attacks. An automated process analyze the NN equation to find weak spots that couldn't be spotted by the designers of the NN. Those weak spots enables the attacking process to create subtle change to the input that are invisible to human experts but confuses the NN. For instance, one can make a NN powered vision AI mistake a washer for a loudspeaker by changing only a few pixels. In this case the lack of explainability makes it impossible for a human too predict defects in the deployed AI.
How XAI makes a difference

In order to study the impact explainability makes on AI projects we are categorizing effects in three stages. Higher stages require higher levels of explainability and have more impact on the resulting AIs. We take the point of view of the industrial world, and look at how explainability can make a difference in the deployment and application of AI.
This work is based on the experience we gathered working and discussing with our customers, partners and community, as a provider of machine learning solutions. Examples are focused on systems based on Machine Learning but the proposed three stages are relevant to any kind of AI.
Stage 1: Explainable building process

In any organisation, just like any IT project, a project leveraging AI aims to have an impact on the daily job of some people. Its goal might even directly be to automate part of worker's job or to help them deliver value they could not before. Especially when AI is involved, affected users can be wary of the new system. In particular they may feel threatened by the automation of some of their tasks, or may not believe that a simple computer program can execute complex tasks correctly. A recommandable method to address those concerns is to involve them in the building of the AI. This is where explainability plays a big role.

In this context, traditional quality metrics such as confusion matrices, r2, RMSE, MAE, etc. are not sufficient to get the future AI user's trust, since they want to know more about the why than about the raw results. Visualization is the first go-to technique. Simply plotting the output against context variables is a good way to get a feel for how an AI performs over the target domain when dimensionality is low. Interactive simulations can help explore the domain to experience how the AI will react. Beyond these techniques which are applicable to any black box computations, more advanced techniques open the hood and make the structure of the AI itself inspectable.
In the following sections describing the subsequent stages, we will talk about techniques able to work while the AIs are live, processing production data, at production speed. These techniques are also well suited for stage 1, where the inspection is offline, with less data and runtime constraints.

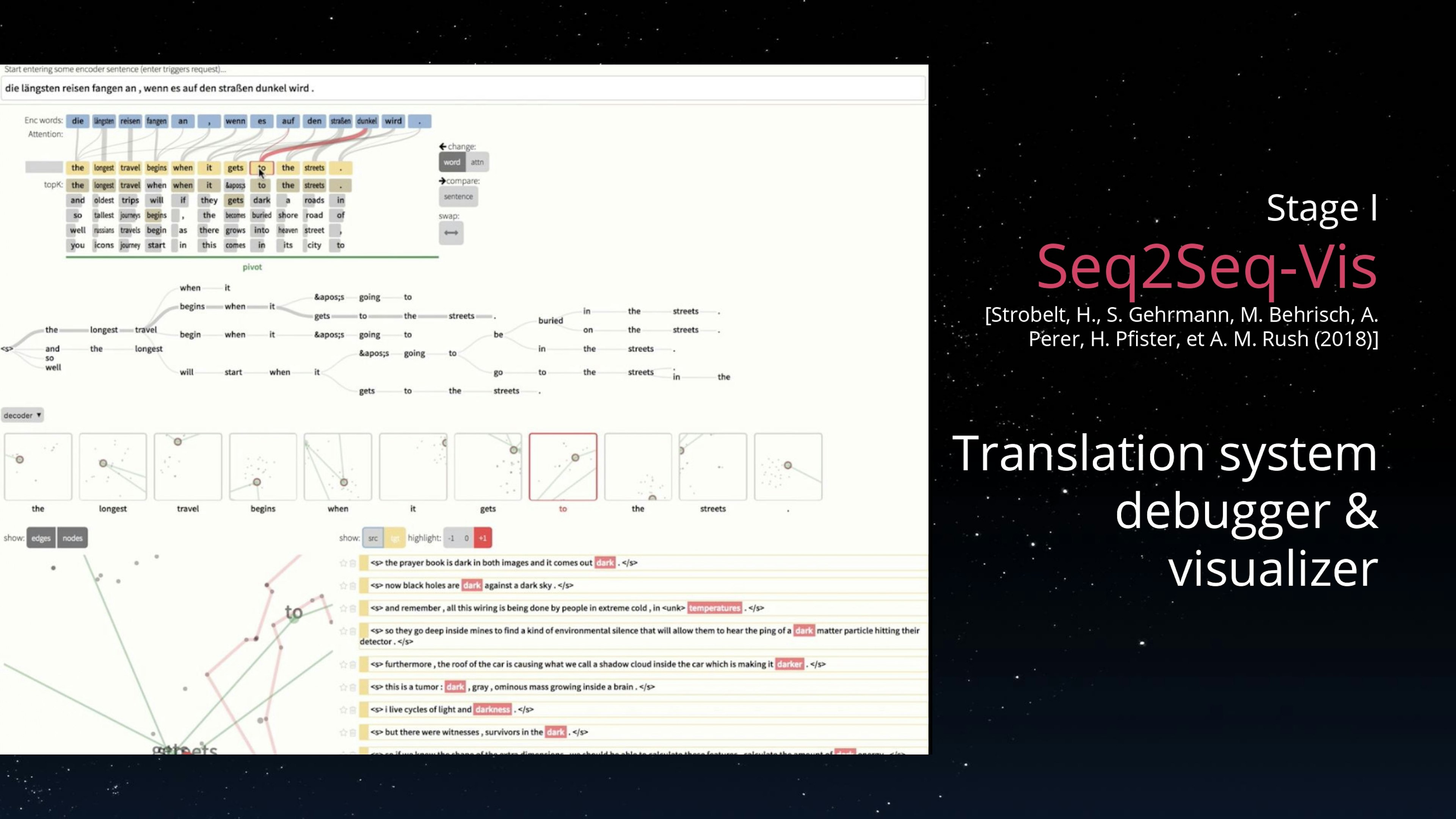
Debugging tools that were initially designed for data scientists can also be leveraged for other stakeholders. AIs powered by neural networks can be inspected by visualizing how intermediate layers react to different input, Tensorflow Playground (playground.tensorflow.org) or ConvnetJS (cs.stanford.edu/people/karpathy/convnetjs/docs.html) are good examples of this approach. On images, the computation of saliency maps (arxiv.org/abs/1312.6034) can also help to convey which parts of the image are considered by the network to make its prediction. This technique led to the identification of the infamous husky vs wolf (arxiv.org/abs/1602.04938) issue in which a wolf is primarily identified by the presence of snow in the picture. Tools like Seq2Seq Vis (seq2seq-vis.io) bring the same kind of debugging capabilities to natural language focused neural networks. This shows that even neural networks, which are considered black boxes, can be at least partly explained offline to the non-technical AI project stakeholder by using the right tools.
While the initial goal of explaining why the AI works the way it does is to ease its adoption, explainability also increases the involvement of potential users by letting them achieve a deeper understanding. As a result they can assist in its development, ensuring that the AI solves an actual problem, and provide valuable feedback on specific behaviors of the AI: instead of providing knowledge upfront, it is always easier to react to what you see the AI doing and why it does it. In many cases, domain experts can easily help if they have an understanding of why the AI makes decisions: sensors having an undocumented validity domain, well-known contexts leading to corrupted data, spurious correlations because of a missing data sources, etc.
The first stage of explainability is about helping create a multi disciplinary team of experts in their respective fields who understand the AI they are building. Offline explainability techniques are key to the acceptance of the future AI and create opportunities to build a better system.
Stage 2: Explainable decisions

Trust in a system is key, especially in an enterprise tool that has an impact on day to day business. Trust makes the difference between a system that is "micro managed" by its users or supervisors, and a system that can enjoy a larger autonomy. The more management a system needs, the more manpower it requires and therefore the less value it has.
Trust is built when a system is not surprising, when it behaves according to our mental model. A system whose limits are understood by its users is arguably more valuable than a more accurate system whose results are considered unreliable. As discussed above (www.cloderic.com), explanations are a good way to accelerate the construction of this mental model. That is where the capacity to explain the AIs' decisions has an impact. That is the second stage of explainable AI.
Stage 1 explainability does not have the same impact: most users or supervisors of AIs did not have the chance to participate in their inception, and in more and more cases, AIs can evolve over time. Furthermore, the ability to access explanations of past AI decisions can help pinpoint root causes and generally provide traceability.

The ability to provide explanations to any AI decision is an active field of innovation with methods such as TreeInterpreter (blog.datadive.net/random-forest-interpretation-with-scikit-learn) LIME (arxiv.org/abs/1606.05386) or SHAP (arxiv.org/abs/1705.07874). Given a predictive model and a prediction, these methods aim at providing a local explanation for the prediction. This explanation takes the form of linear factors that can be applied to input features to reach the predicted results, thus giving an idea of the local feature importance and behavior of the model. The computed feature factors can also be used to generated counterfactual examples and give an idea of the trend of the predicted value given changes in the input features.
An interesting property of this class of algorithm is that they can work using a feature set that is different from the actual feature set used by the model. It is therefore possible to adapt the explanation by making it more comprehensible to the explainee, independently from the features that yield the best predictions. This additional feature engineering step is not without risk, Christophe Denis and Frank Varenne (hal.sorbonne-universite.fr/hal-02184519) argue, it can be used to convince explainees to blindly trust said AI, by presenting a deceptive approximation instead of bringing more transparency.


A good example of SHAP usage can be found in the banking fraud detection solution provided by Bleckwen (www.craft.ai/blog/ai-night-2019-explainable-ai-workshop) company. One key part of the solution is a predictive model, trained on labelled datasets containing fraudulent and non-fraudulent transactions. This model computes a score for each transactions. Transactions having a score above a certain threshold are reviewed by a human expert to confirm their fraudulent nature. One of their customers' requirements is to get explanations for every score. They chose to use non-explainable gradient boosting techniques for the model on a range of complex features. The local explanation is computed by SHAP on a range of features they designed with their end users to make them completely understandable to them.

Another example of stage 2 explainable AI is how Dalkia uses machine learning as a part of their energy management dashboard (www.craft.ai/blog/client-ia-dalkia). Here, decision trees are used to predict an energy diagnosis based on labelled data streams. Predictions are used as diagnosis recommendations in the energy managers' dashboard, and explanations are extracted from the decision tree as a set of rules that were applied. What's really interesting in this example is that without explanations alongside the recommendations this AI would not have any value. At its core, the goal of the system is to help energy managers handle more data points. Without an explanation, when provided with a prediction, energy managers would need to investigate the raw data in order to confirm or contradict it. They would end up doing the same amount of work as without explanations. When an explanation is provided, this counter investigation is only needed when the energy manager disagrees with it. Here, explanations are needed for the business value of the AI.
Stage 3: Explainable decision process

Stages 1 and 2 are about helping humans create a mental model of how AIs operate. This enables humans to "reason" about the way AIs work critically, and decide when to trust them and accept their outputs, predictions or recommendations. To scale this up to many AIs and over time, you need to define business logic that will apply the same "reasoning" automatically. Stage 3 is about enabling interoperability between AIs and other pieces of software, especially software that uses business logic.
When discussing AI, and especially models generated through machine learning, we often talk about the underlying concepts they capture, for example convolutional neural networks are able to recognize visual patterns and build upon these lower level "concepts" in their predictions. AIs that can explain those lower level building blocks, make them inspectable to business logic, reach stage 3. Such AIs ultimately act as a knowledge base of the behavior they model.
Stage 3 explainability makes a difference especially when a lot of instances of evolving AIs need to be supervised by business logic, for example in a context of continuous certifiability or collaborative automation between machine learning based AIs and business rules.

This level of explainability requires fully explainable AI. Machine learning techniques such as linear regressions or decision tree learning can reach such levels. Another approach is to approximate a more "black box" model with a more explainable model, for example RuleFit (arxiv.org/abs/0811.1679) is able to learn a minimal ensemble of rules from a tree ensemble method such as Random Forest.

An interesting example of level 3 explainability is Total Direct Energie's energy coaching feature (www.craft.ai/blog/how-total-direct-energie-applies-explainable-ai-to-its-virtual-assistant) that is part of their customer-facing mobile application. It generates personalized messages for each customer. At its core, the system is made of a machine learning-based energy consumption predictive model, and a business expertise-based message generation and selection module. The predictive model is made of individual regression trees, each updated continuously from the data of a single household. The message generation module is generic for all users, and uses the model's explanations and predictions as input data to select and personalize each message. So the predictive models provide an understanding of the household's energy consumption behavior, which is automatically processed to generate personalized messages.
When presented with a visual explanation of a decision process, people tend to navigate through its structure to understand the process. Stage 3 is about letting software programs, other AIs, do the same thing, thus unlocking a wealth of additional use cases.
Challenges
While there are already deployed AIs covering these three stages, there are still challenges ahead before explainable AI can be generalized.
Evaluating explanations

In the previous sections we discussed how certain techniques bring more or less explainability, however we did not discuss how we can make such an assessment.
Ad-hoc experiments or KPI can be used. For example the D-Edge company, which provides pricing recommendations to hotel managers among other services, measures whether explained recommendations are accepted. Every recommendation is accompanied by a natural language explanation. Managers can accept and apply the recommendation to their pricing or discard it. As presented during a round table focused on XAI (www.craft.ai/blog/ai-night-2019-explainable-ai-workshop), they consider the proportion of accepted recommendations as a proxy measure for the quality of their explanation. We believe that this makes sense, as hotel managers need to be convinced to make such an impactful change to their business.
In the general case, other proxy measures can be used, such as the number of rules, nodes or input variables considered in an explanation or explainable model. However these lack generality: how can the explainability of a linear regression and of a regression tree be compared? They also lack an experimental, measurable ground truth: for example we do not know if humans find that the explainability provided by LIME grows exponentially or linearly with the number of features involved. Furthermore, as discussed above (www.cloderic.com), what constitutes a good or a bad explanation depends on the recipient of the explanation and their own cognitive biases. This poses an additional challenge to this evaluation. There is a lack of a systemic framework or objective criteria to evaluate the explanations provided by AIs. A challenge identified by Adrian Weller (arxiv.org/abs/1708.01870).
Improving the performances of XAI

The AI community generally considers that the more explainability you gain, the less predictive performance you can achieve, especially in Machine Learning. Overcoming this is a primary goal of the XAI field, and in particular it is the main goal of the DARPA XAI program.
Several opportunities have been identified to achieve this objective, the most promising ones being to create hybrid AIs combining different approaches.
One idea is to push high-performance but unexplainable algorithms to the edges, around an explainable core. For example a deep neural networks would identify low level details like whiskers and pointy ears, while decision trees or bayesian models would associate the presence of both whiskers and pointy ears to a cat in an explainable fashion.
Another idea is to adapt Machine Learning algorithms to work from existing expert-built symbolic representations of physical models to leverage existing knowledge, instead of having to relearn and embed it. This field is relatively new, and comes as a stark departure from the deep learning trend of the past few years. This is at the heart of IRT SystemX IA2 program (www.irt-systemx.fr/systemx-lance-le-programme-de-recherche-intelligence-artificielle-et-ingenierie-augmentee-ia2/).
Conclusion

We structured in three stages the impact that explainability has on AIs deployed in the "real world". Those 3 stages provide a simple framework to quickly identify the need for explainability in a AI powered project.
Stage 1 is about leveraging explainability to improve the adoption and performance of AIs.
Stage 2 is about explaining every AI decisions to build trust with their users and supervisors.
Stage 3 is about enabling the interoperability of AIs with each other and other software, thus unlocking new and richer use cases.

Because we focused on what explainability enables in AI, we did not discuss regulation. However it is important to note that initiatives such as the European GDPR pave the way for a "right to explanation" (iapp.org/news/a/is-there-a-right-to-explanation-for-machine-learning-in-the-gdpr) which will require, at least in some cases, a stage 2 requirement. We strongly believe that stage 2 explainability is a key to actually operationalize enterprise AI because it not only offers stronger guarantees in terms of data governance, but also facilitates involvement and support from users and domain experts impacted by such AI.
Far from being just a constraint on AI design, explainability is actually an opportunity to develop AIs that actually deliver value to Humans.

Peer-reviewed publication
Paper, as published in the proceedings of the "Humains et IA (HIA)" workshop of the 20th Extraction et Gestion des Connaissances (EGC) conference in 2020 (egc2020.sciencesconf.org).
History
- 2019/03/13 - Paris Machine Learning Meetup #5, season 6 (nuit-blanche.blogspot.com/2019/03/ce-soir-paris-machine-learning-5-season.html).
- 2019/04/18 - AI Night explainability roundtable (www.craft.ai/blog/ai-night-2019-explainable-ai-workshop).
- 2019/05/24 & 2019/07/18 - #AIforLeaders workshops at Total (sc21.fr/total-retour-sur-la-session-aiforleaders-du-24-mai/).
- 2019/10/07 - X-IA #6 Intelligibilité des modèles Meetup (ax.polytechnique.org/newsletter/preview/index/id/503/noLayout/1)
- 2019/10/17 - Séminaire Aristote, l’IA est-elle explicable ? Un coup d'oeil furtif dans la boite noire des algorithmes de l'IA (www.association-aristote.fr/lia-est-elle-explicable/).
- 2020/01/28 - Humains et IA (HIA) workshop (headwork.gforge.inria.fr/HIA2020/index) of the 20th Extraction et Gestion des Connaissances (EGC) conference.