
This article was originally published on The Good AI a collaborative media launched by Caroline Lair (www.linkedin.com/in/carolinelair/)
As soon as AIs started to be deployed in the “real world”, they started to be accused of being biased. Are AIs inherently racist or misogynistic, do they always support the status quo ? Recently, while exposing a weird background detection “bug” in Zoom resulting in the erasure of his black colleague’s head, Colin Madland (twitter.com/colinmadland) found out a similar issue in Twitter picture cropping algorithm.
Tweet not found
The embedded tweet could not be found…
As always the debate raged between people denouncing the bias in the algorithm and those stating the development team reproduced their own biases. In this article I want to help you understand how AIs end up reproducing such biases and what can be done about that.
Our story starts as a local bakery chain gets a new CEO, who decides to digitalize the stores’ supply chain to better suit their customer needs and improve efficiency. In particular, they decide to develop an AI able to orchestrate the production, based on predicted sales of each item for each point of sale. Because the new CEO doesn’t know much about bread and pastries, they decide to take a fully data driven approach. “We are at the forefront of the baking-tech wave, we don’t want to be biased by old-world ways of thinking. The truth is in the data!” they say in an interview.
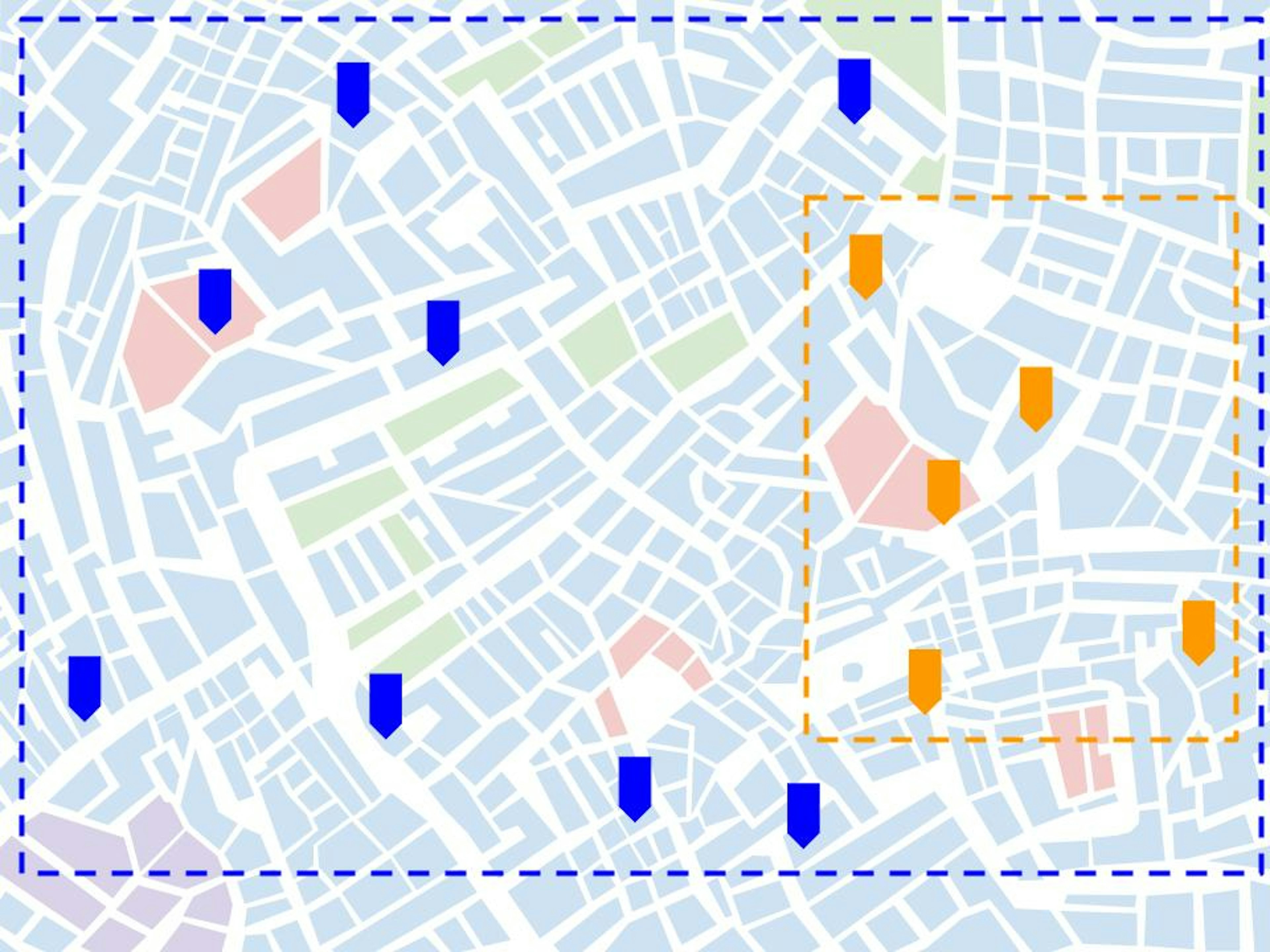
Selection bias is caused by a different scope between the data used to design the AI (in orange) and the data on which it operates (in blue).
As soon as the newer stores open on the east side of the city, they use the new stock management system providing a constant data stream from each location. The data scientists can fine tune and validate the AI with real world data. After a few weeks, the AI is successfully deployed. Quickly the theoretical benefits become reality: the east side stores have less unsatisfied customers, as baguettes or religieuses are always in stock when ordered, and, at the same time, discard fewer goods, as overproduction is reduced. This success triggers the full deployment of the AI to the rest of the city as historical locations get retrofitted with the new stock management system. After a while, however, a growing number of stores gets less impressive results from the AI, items are regularly out of stock. The data science team, not knowing what’s going on, immediately blame the managers of the newly equipped store, accusing them of bypassing the system because of their bias against technology. On their side they anticipated all the issues: they made sure that the AI could differentiate each store to take into account the specificities of their customer base, they also devised a data balancing module to compensate for the smaller data history in newly equipped stores. What they didn’t think of, they found out a few days later, is that the consumption habits are vastly different from one area of the city to another. In the touristy east side, where the data they used during development come from, customers mostly buy about ten types of items, visitors mostly look for the iconic breads and pastries: croissants, baguettes and éclairs. Whereas in the rest of the city’s stores, located in residential neighborhoods, the habits are much more spread out. The way they parametrized the algorithm worked really well on the former but not so much on the latter. This is a sneaky example of selection bias, the clearly experienced data scientists were ready for most of the issues, they knew the data used during development were not fully representative. However, they didn’t anticipate a huge change in underlying behaviors that could necessitate AI architecture changes. Anticipating that there is a bias is relatively easy, anticipating the nature of this bias is more complex. When the scope of an AI evolves, some manual work is always required.
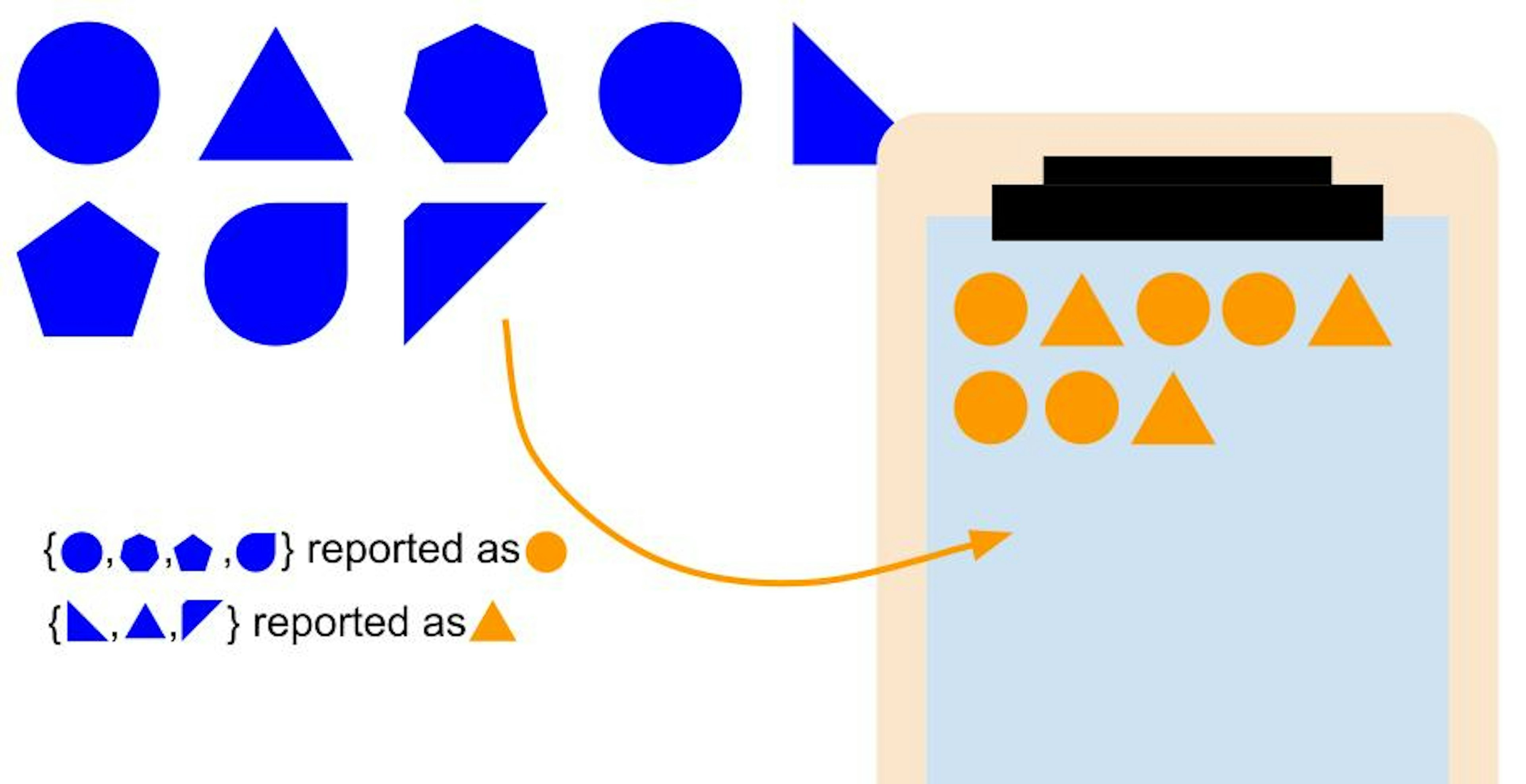
Reporting bias appears when the data reported to the AI (in orange), oversimplifies the reality (in blue).
The store specificity problem solved, the operations continued with great success. There was however one store that showed a weird behavior, no alarm was raised from the AI but there were less and less customers at the store. The headquarter management started to blame the data scientists, who didn’t quite understand the issue as the AI’s predictions were consistently good. Taking a deeper look at the data, they discovered that this store only had a few kinds of items in stock, weird but consistent with the data as it was the only ones being bought here. An investigator was nevertheless dispatched to the store, he found out that the cashiers were trained to select the first item matching the price of what the customer had ordered, it surely worked for accounting but not for production… The store’s team were really receptive to the internal communication about the AI and trusted it fully, that's why they didn't question receiving less and less types of items. This reporting bias was identified because customers got fed up of having no choice and didn’t return to the store. How did it occur? Employees did not have any knowledge of how the AI worked, they didn’t realize it relied on them to do its work properly and just blindly trusted it. Contrary to the previous issue, this bias in the data didn’t lead to a badly performing AI in isolation but to an AI having a direct negative effect on the outside world. This was soon solved by training the employees and providing them with a better toolset to understand and monitor the AI.
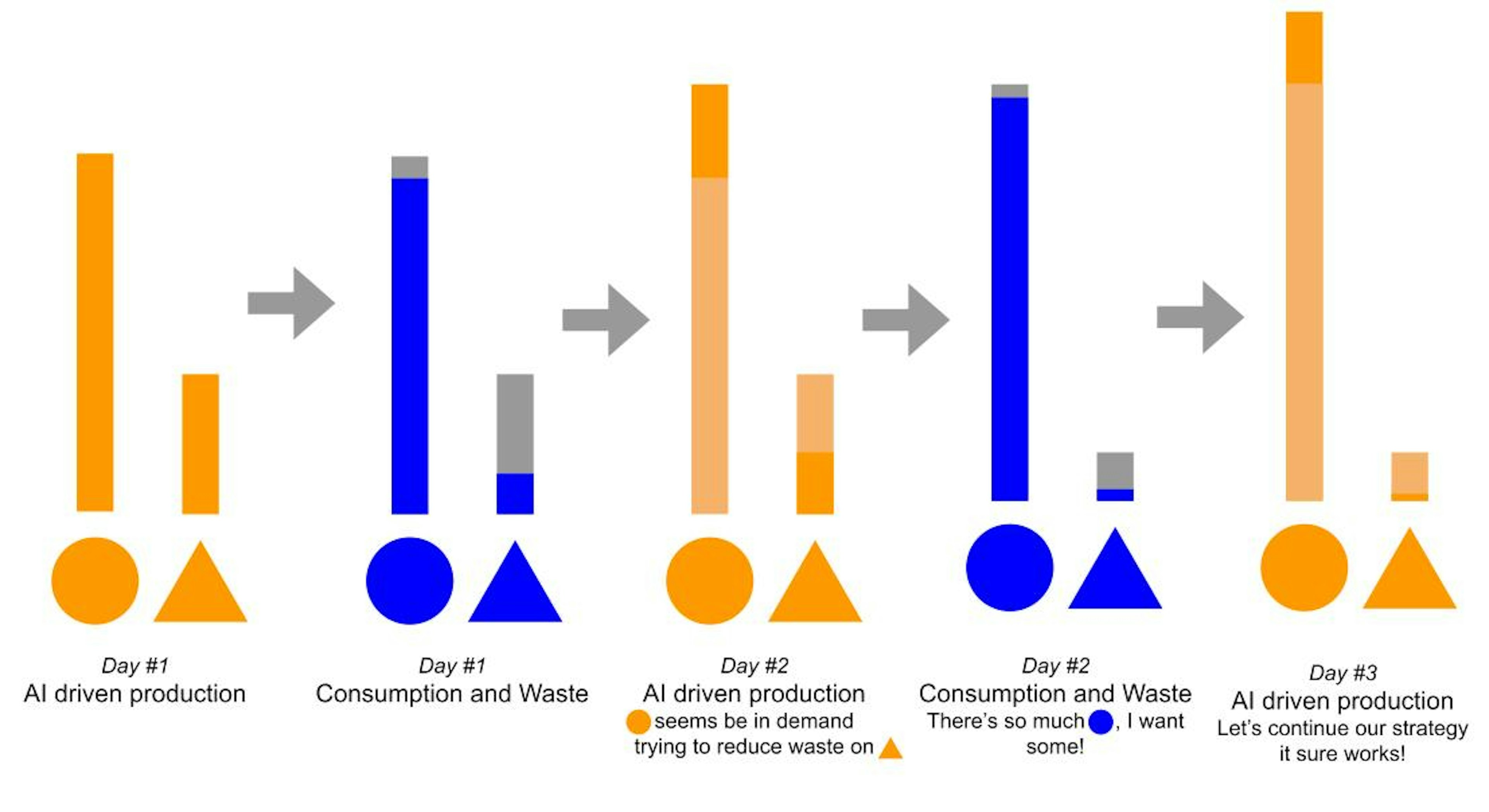
Bias amplification appears when an AI takes advantage of an observed bias to fulfill its objective.
The AI driven business of the bakery chain caught the attention of a local investigation journalist. They compared the methods and results of the bakery chain and its competitors. The key business metrics were impressive but they found out that the fruit based recipes were less available in the stores than other cream and butter based pastries. After a few months their presence was even reduced. The success of the company led other bakeries to imitate them, going further towards the extinction of pies and crumbles. The full investigation was published and quickly, the scandal broke, #wewantfruits was trending for a full week, the fruit defense league got upset and asked for the removal of the CEO in an open letter ; everyone was blaming the AI in this matter. This was really bad publicity for the bakery chain. The data science team got to work, trying to understand what went wrong. After days of investigation they found nothing, no missing data, no biased distribution, no skewed validation metrics, everything was working fine, the AI was leveraging the data, making relevant decisions and the turnover of every store was growing steadily. When being accused of skewing the AI predictions towards the more profitable butter based pastries, the head of the data science team gave an interview: “Our AI is not trying to optimize for some objectives, it only tries to limit waste and let the customer buy what they want, it doesn’t have an evil plan on its own!”. He was right. The story told by the data was pretty simple, when the only remaining pastries at the end of the day were strawberry tarts or apple crumbles they stayed on the shelves and were not picked by the customers, when it was éclairs or flans, most were sold. Slight customer preference? Better shelf life with less fruit? The root cause was fuzzy but the AI learned that less fruit based product meant less waste. This phenomenon was actually continuously amplifying, the trend was clear, in a few months, completely removing fruit based recipes would lead to more turnover. The fruit supporters social media campaign was becoming very vocal and a growing portion of the customers were considering a boycott. What looked like a virtuous circle from a pure short term business perspective was turning into a vicious circle from a PR and public health standpoint. The data science team was told to “fix this biased AI, quickly”.
Among the data science team, the debate was heated: “we are only giving the people what they want, if it’s not good for them, it’s not up to us to tell them, we’re just a business”, “we have a social responsibility in what we build, we need to build responsible AIs”... Technically there were tons of ways to give a boost to fruit based recipes: skew the input data to give more weight to fruit based recipes sales, give an additional “diversity” objective to the AI itself, apply to the AI raw output a different scale for these recipes… In fact to fix this perceived bias in their well oiled machine, the data scientists would need to introduce a specific bias. The decision was made, they implemented it in a matter of days and a few weeks later, apple pies and apricot crumbles were back in force. Operations were less optimal but the brand was saved and the customers, a little healthier.
This little tale hopefully helped you to get a better understanding of what’s going on when an AI is accused of bias. We described a few examples of biases falling in two basic categories. On one hand we talked about selection bias and reporting bias creating discrepancies between the data the AI is operating on and the real world, leading to short term performance issues. These are often the cause of a big performance gap between a working prototype and an operationalized AI. The issues we introduced this article with are probably of that nature, it seems the teams at Zoom and Twitter failed to recognize that the data they used to develop and test their AIs weren’t representative.
On the other hand, we have a perceived bias that already exists in the “real world”. AI, and statistics in general, will often fall into this trap and amplify them, in the best case resulting in an increased awareness of the underlying issue, in the worst case perpetuating it. That’s the kind of issue Amazon faced a few years back when building an AI to screen resumes (www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G), its behavior was representative of the company’s actual processes, including their biases.
Thinking of AI, data science or statistics as something pure and only driven by data is a fallacy. Issues happen because of design choices made by Humans and are solved thanks to the expertise and ethics of Humans. At the same time, AI helps identifying and quantifying biases existing in our societies. Fostering the collaboration between Humans and AIs is key to the development of good AIs.